まず,広範囲における能動的観測を行うために,我々は視点固定型パン・チルト・ズームカメラを開発した.このカメラは,投影中心と回転中心が常に一致するように較正されており,パン・チルト・ズームパラメータを変化させながら画像を撮影しても,画像間に視差が存在しないという性質を持つ.この性質により,(1)撮影画像集合から1枚のパノラマ画像を生成可能である(図1),(2)生成されたパノラマ画像から任意のパン・チルト・ズームで撮影される画像を抽出可能である(図2).こうした特性を利用することによって,任意のパン・チルト・ズームで観測された入力画像と生成背景画像との比較(背景差分)により対象物体の検出を行うアクティブカメラシステムが実現可能となる.
図1:
ワイドパノラマ画像(180枚の観測画像から生成)
 |
図2:
背景差分による対象検出
(左:観測画像,中:生成背景画像,右:差分画像)
 |
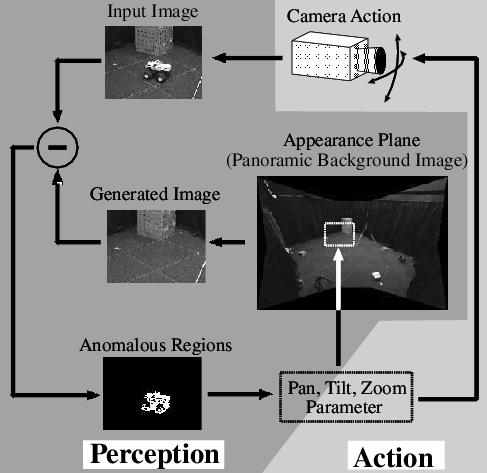
次に,単一のアクティブカメラによる実時間対象検出・追跡のために,視点固定型パン・チルト・ズームカメラを用いた能動的背景差分法を提案する(図3).このシステムでは,システムの持つ視覚機能とカメラ制御機能をそれぞれ並行に動作するモジュールによって実現し,ダイナミックメモリを介した両機能間の実時間相互作用により,シーン中を移動する追跡対象の継続的追跡を実現している.ダイナミックメモリとは,並列プロセス間の情報交換のための共有メモリである.ダイナミックメモリを介するにより,各プロセスは非同期且つ任意のタイミングで,任意の時刻に観測された情報を獲得することが可能となる.このように画像観測・処理を行う視覚モジュールとカメラ制御を行う行動モジュールが動的インタラクションを行うことにより,ストップアンドセンスを繰り返さなければならなかった従来の能動的背景差分法と比べ,対象移動への追従性の高い滑らかなカメラ制御による対象追跡可能になった(実験結果 [動画] ).
図3:
視点固定型カメラに利用した視覚・行動モジュールによる能動的背景差分
 |
能動視覚エージェント群の実時間協調動作を実現するために,我々は三層構成のインタラクションシステムを提案する.
- 第1層(intra-AVA層): 一つの能動視覚エージェント(Active Vision Agent,略してAVA)を構成する視覚・行動・通信モジュールと,これらのモジュール間の情報交換を行うダイナミックメモリが存在する層である.これらのモジュール群は,相互に必要な情報を交換しながら動作することにより,一つのAVAとして機能する.
- 第2層(intra-Agency層): 特定の対象を協調追跡しているAVAのグループをエージェンシと呼ぶ.この層は,一つのエージェンシに所属するAVAによって構成される.同一エージェンシ内のAVA群は,互いの対象検出結果を交換・統合することにより,追跡対象の協調追跡を実現している.また,各エージェンシ内にはそれぞれダイナミックメモリが一つ用意されており,各AVAはこのダイナミックメモリを介して情報交換を行う.ここでダイナミックメモリの機能を利用することにより,各AVAで検出された非同期な対象情報から安定な対象同定結果を得ることができる.
- 第3層(inter-Agency層): システム内の全エージェンシにより構成される層である.各エージェンシは,相互に追跡対象とエージェンシの構成情報を交換する.こうして交換された情報に基づいて,エージェンシ間で所属するAVAを交換することにより,追跡対象の移動に応じた適切なエージェンシ構成を実現する.
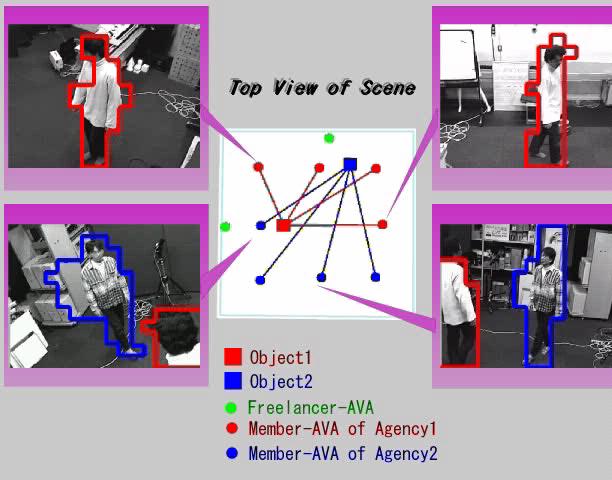
本システムでは,各層における動的相互作用によって,システム全体として複雑な動的状況下における複数の移動対象の実時間追跡を可能としている(実験結果 [動画] .スナップショットを図5に示す).
図4:
3層構成アーキテクチャ
(下:intra-AVA層,中:intra-Agency層,上:inter-Agency層)
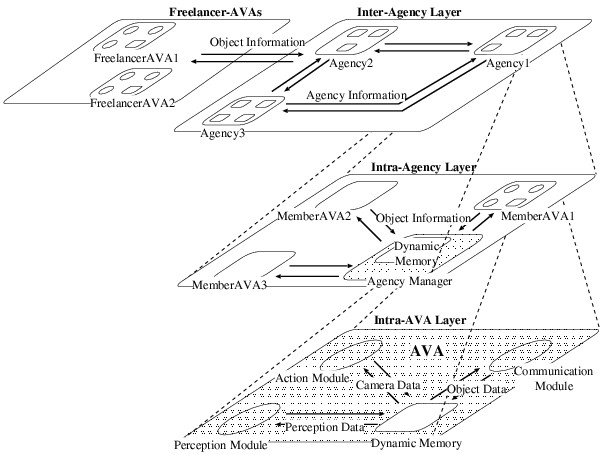 |
図5:
実験結果(スナップショット) [動画]
 |